 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCSC at SemEval-2025 Task 3: Context, Models and Prompt Optimization for Automated Hallucination Detection in LLM Output
May 05, 2025Hallucinations pose a significant challenge for large language models when answering knowledge-intensive queries. As LLMs become more widely adopted, it is crucial not only to detect if hallucinations occur but also to pinpoint exactly where in the LLM output they occur. SemEval 2025 Task 3, Mu-SHROOM: Multilingual Shared-task on Hallucinations and Related Observable Overgeneration Mistakes, is a recent effort in this direction. This paper describes the UCSC system submission to the shared Mu-SHROOM task. We introduce a framework that first retrieves relevant context, next identifies false content from the answer, and finally maps them back to spans in the LLM output. The process is further enhanced by automatically optimizing prompts. Our system achieves the highest overall performance, ranking #1 in average position across all languages. We release our code and experiment results.
Lightweight Dual-channel Target Speaker Separation for Mobile Voice Communication
Jun 05, 2021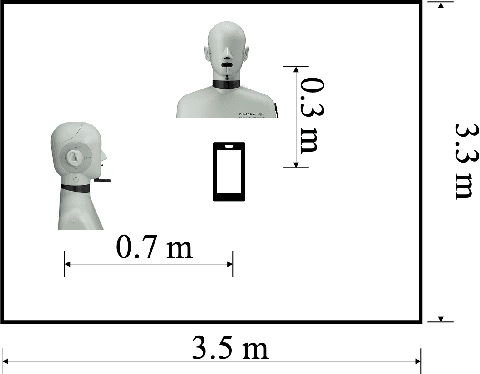
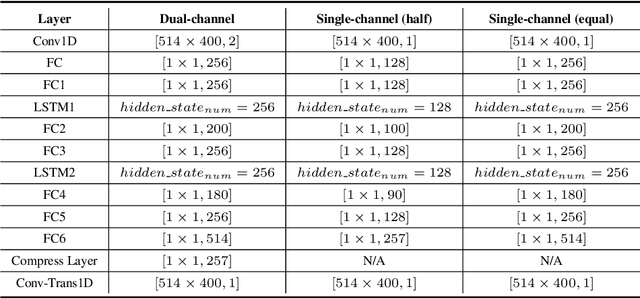
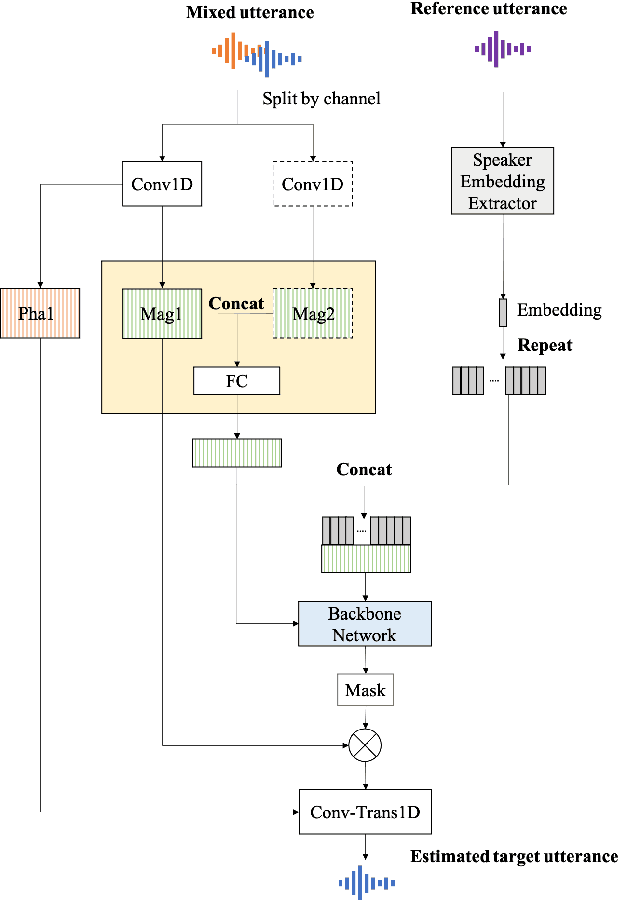
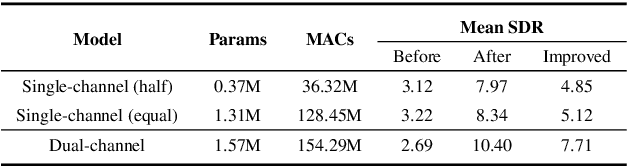
Nowadays, there is a strong need to deploy the target speaker separation (TSS) model on mobile devices with a limitation of the model size and computational complexity. To better perform TSS for mobile voice communication, we first make a dual-channel dataset based on a specific scenario, LibriPhone. Specifically, to better mimic the real-case scenario, instead of simulating from the single-channel dataset, LibriPhone is made by simultaneously replaying pairs of utterances from LibriSpeech by two professional artificial heads and recording by two built-in microphones of the mobile. Then, we propose a lightweight time-frequency domain separation model, LSTM-Former, which is based on the LSTM framework with source-to-noise ratio (SI-SNR) loss. For the experiments on Libri-Phone, we explore the dual-channel LSTMFormer model and a single-channel version by a random single channel of Libri-Phone. Experimental result shows that the dual-channel LSTM-Former outperforms the single-channel LSTMFormer with relative 25% improvement. This work provides a feasible solution for the TSS task on mobile devices, playing back and recording multiple data sources in real application scenarios for getting dual-channel real data can assist the lightweight model to achieve higher performance.